Introduction to Diagonalization, Eigenvalues, and Eigenvectors
Finally cracking how to diagonalize a matrix without hunting for the right basis — turns out eigenvalues and eigenvectors are the secret the whole time!
Picking right up where we left off.
The question we got stuck on — “Ugh!!!! How do I actually find R?!?!?!?!!!” — right???
Like, how on earth are you supposed to go hunt down the right basis~~!!!!!!!
Yeah yeah yeah yeah, apparently finding that basis is genuinely brutal.
BUT — turns out you can pull off diagonalization without ever knowing the right basis!!!!
Let’s go figure out how!!!
The trick: sneak up on it from the other side. Look at a matrix that’s already diagonalized and read the clue off of it.
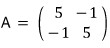
We weren’t trying to diagonalize anything back then,
but in the basis-change section — looking at it now — when we did a basis change, we’d accidentally diagonalized something.
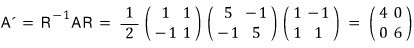
That expression I wrote like that — I want to rephrase it like this now.
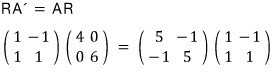
Here’s how I want to read this result.
Split it. Treat it as the column-1 column vector and the column-2 column vector, separately.
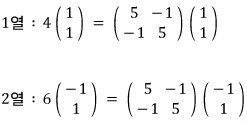
Wait wait WAIT?!?!?! When we hit some vector with our original matrix A,
it came out as that same vector times a scalar?!?!?!!!!!!!!
This property… if we can find 2 vectors with this property for matrix A,
AND find that ‘scalar’!!! — boom, diagonalization!!!
Let’s start with a 2x2 matrix.
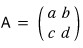
We want 2 vectors with that property for this A. Call them
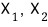
and call ’that scalar’ for each one
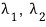
And I’ll write the relationship like this.
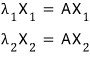
That holds, right.
One expression that bundles both of them together —
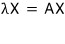
— let’s go with that and keep moving.
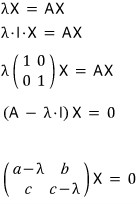
Oh hey!!!!!!!!!!!!!! That’s a homogeneous equation!!!!!!!!!!!!!!
And here’s the deal — if the matrix is invertible, the only solution is the trivial one……..
And we really don’t want X to come out as the zero vector (the trivial solution).
Because if X = 0, that means R is non-invertible,
which means A’ = R⁻¹AR doesn’t even hold!!! We have to block the situation where X is forced to be trivial!!!!!!
In other words,
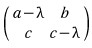
this matrix has gotta be non-invertible!!!
So,
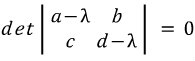
has to hold!!!!!!!!!!!!!!
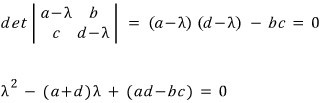
A quadratic.
Hmmm~~ a quadratic you can crack with the quadratic formula, right????????
Like that, the two lambdas that satisfy it —
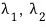
— pop out.
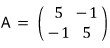
In matrix form, shall we go find
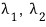
?!?!?!?
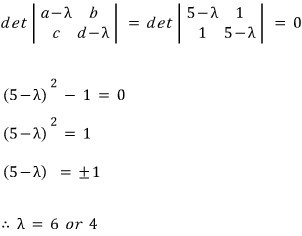
Now, for each
I want to find the X that goes with it!!!!
The ones we just found —
— those.
Plug each into
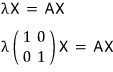
and find the X that works.
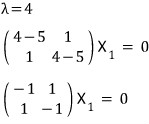
The X1 that satisfies this — if you stare at it for a sec,
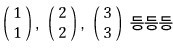
there are a TON of them!!!!!
Same deal for X2,
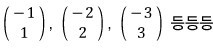
a whole bunch.
OK so, grab one X1 and one X2, line them up side by side,
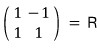
we can call this our R and go find A’.
If we run the same play on an n x n matrix,
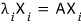
we need to dig up n vectors and the scalar values that satisfy this,
(I’m getting tired of saying “vector” and “scalar” over and over —
the vector and scalar that satisfy this kind of equation are called the eigen-vector and eigen-value, apparently.)
The naming makes sense — once you fix A, these things follow from it uniquely. That’s the idea.
So, like we just learned,
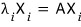
to find the lambda and x that satisfy this, we write it in matrix form,
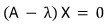
and to block the trivial-solution-only situation,
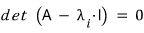
this absolutely has to hold — we know that now.
When that condition kicks in, an n-th degree equation in λ pops out,
and once we extract all n lambdas from that n-th degree equation,
with those lambdas we find X1 through Xn, with X1 through Xn we build the coordinate transformation matrix R,
and via A’ = R⁻¹AR we finally diagonalize A.
What does A’ end up looking like? —

— we can guess from the 2x2 example above!!!!!!!!
(It’s NOT always going to look exactly like this.
Which means — there’s an assumption I’ve been quietly making without telling you —
I’ll roll that assumption out little by little starting in the next post, and from here on we go case by case.)
And to wrap up this post —
let me toss out a few reasons diagonal matrices are nice.
① The geometric meaning becomes super easy to see!!!!!!
When you take the matrix
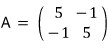
and hit it on the eigenvectors
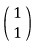
&
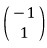
and what comes out is, respectively,
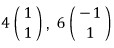
— what this means is that the linear map A is doing this:
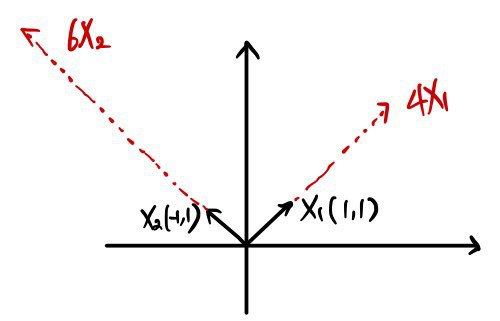
hitting X1 with A scales it by 4 in that direction,
hitting X2 with A scales it by 6 in that direction —
the geometric meaning is right there for free!!!!
And using this, when an arbitrary vector gets multiplied by A, you can also figure out what vector pops out, easy!!!!
For example,
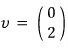
decompose it using the X1, X2 we found.
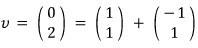
Then,
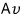
what this turns into — easy to see~~~ is what I’m saying heh heh heh.
②
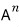
(powers) become a piece of cake!!!!!!
A matrix is fundamentally a linear map — it takes some vector and spits out a different vector,
and when we want to know
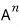
— the thing that applies this transformation over and over —
if we use
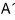
then,

③ Plugging a matrix into a function written as a Taylor expansion.
OK so what I mean is —
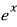
written as a Taylor expansion becomes
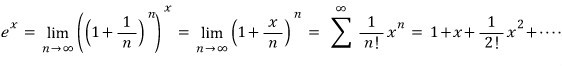
and if you sub matrix A into this function,
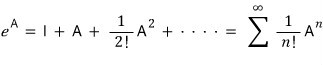
powers of A show up everywhere — so doing the ② trick again makes it easy heh heh heh heh.
Anyway, diagonal matrices are great for handling the power-of-A pieces that pop up in a Taylor expansion!!!!
③ Systems of differential equations become easy to solve!!!!
When an equation shows up, what you’re trying to do is “find the unknown that satisfies it.”
But when a differential equation shows up, what you’re trying to do is “find the function that satisfies it.”
So a system of differential equations — the goal is finding the functions that satisfy everything ‘all at once’!!!!!!
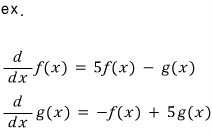
Let me put this in matrix form.
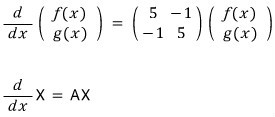
So now we need to find the X that satisfies this!?!?!?!?
And here — if we use a diagonal matrix!!!!!!

The instant it’s written as a diagonal matrix, the tangled cross-talk between the functions vanishes, and it turns into a differential equation you can actually handle.
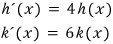
How to actually solve the differential equation — gonna skip.
This is linear algebra time.
Check this out instead.
http://gdpresent.blog.me/220341671707

Differential equations special post.
If you’re a college STEM undergrad you bump into “(linear) differential equations” an absurd number of times, so I’m thinking about doing a post on this topic…
blog.naver.com
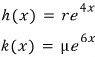
Solved, easy!!!!!!!
That’s why diagonal matrices are nice.
And like I said earlier — from here on out we go case by case!!!!!!!!
Everything above is honestly just a simple intro to diagonalization.
The real diagonalization stuff kicks off in the very next post.
Originally written in Korean on my Naver blog (2016-01). Translated to English for gdpark.blog.
Comments
Discussion happens via GitHub Discussions. You'll need a GitHub account to comment.