Minimal Polynomials, Companion Matrices, and More
Diving into minimal polynomials and their sneaky relationship with characteristic polynomials — turns out it's the same divisor-hunting logic we used back in number theory!!!!
Picking right back up where we left off!!!!
The set
$I_{A}$
is
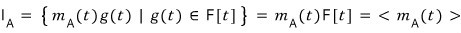
and we said it’s closed under addition, subtraction, and multiplication.
But hold on — when we did integers, didn’t we say that any set of polynomials that’s closed under addition, subtraction, and multiplication can be called “the set of multiples of some polynomial”?????
So we can write it as
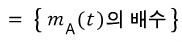
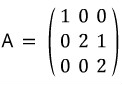
(Yep — same setup as in number theory….. go peek at the earlier post if you need to.)
$$m_{A}\left( t \right) \quad :\quad \text{minimal polynomial}$$is what we call this guy.
Aaahhhh and also — this minimal polynomial, when you plug A into it, also has to give 0!!!!!
So it’s the lowest-degree polynomial out of all the ones that vanish when you plug the matrix in!!!!!
Got it?!?!?!
OK so let’s look at the relationship between the characteristic polynomial and the minimal polynomial!!!
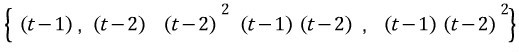
if this exists,
the characteristic polynomial is
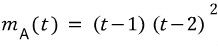
OK OK.
$\varphi_{A}\left( t \right)$
is also in
$I_{A}$
so it’s a multiple of
$m_{A}\left( t \right)$
too — a multiple of what though~~~~~~~
What that means is — among the factors (same idea as divisors) of
$\varphi_{A}\left( t \right)$
there’s gotta be
$m_{A}\left( t \right)$
sitting in there somewhere.
Hmm~~~~~
If we list out all the factors (= divisors) of
$\varphi_{A}\left( t \right)$
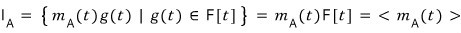
the minimal polynomial has to be one of these!!!!! Which one though…..
The method’s pretty simple: just go through them from smallest up, plug A in one by one, and grab the first one that gives 0.
Doing that, the minimal polynomial of A turns out to be

so the minimal polynomial is the characteristic polynomial…..T_T T_T T_T
Ahhh but — if the matrix had been like this,
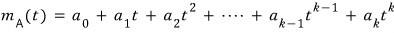
then the characteristic polynomial and the minimal polynomial are
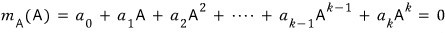
different from each other…………………………….T_T T_T T_T T_T T_T T_T oh god………………….
Just stripping out the multiplicity isn’t enough to give you the minimal polynomial……..
(Apparently there’s no general rule or formula for finding the minimal polynomial…. you just have to check them one by one.)
The proof is easy though, so I’ll skip writing it out and just say it in words.
The minimal polynomial,
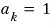
isn’t one of these 5 cases —
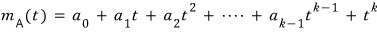
it’s one of these two.
Did you catch that??? It’s restricted to the cases that include all the different kinds of divisors!!!!!
This is supposedly one of the easier ways to find the minimal polynomial…
The reason we’re learning about the ‘minimal polynomial’ — which you can think of as one attribute of a given matrix — is that we’re going to need it to dig deeper into decomposition theorems later, apparently.
But this isn’t enough. Let’s push the minimal polynomial story just a little further!!!!!
(One more step to go……)
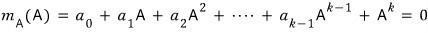
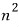

By Cayley-Hamilton, we already know that plugging A into the characteristic polynomial
$\varphi_{A}\left( t \right)$
gives 0,
so the characteristic polynomial is in
$I_{A}$,
and on top of that,
$\varphi_{A}\left( t \right)$
is a multiple of
$m_{A}\left( t \right)$
!!!!!
So we can write
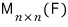
But that all came together easily because we knew C-H.
So this time we’re going to define the minimal polynomial from scratch, pretending we don’t know C-H.
There’s a reason we need to do this!!!!!!!
Let me start by hypnotizing myself first:
“I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0. I do not know that plugging A into the characteristic polynomial gives 0.”
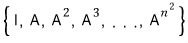
let’s just assume this.
When we substitute A,
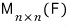
this has to give the zero matrix.
That’s literally the condition for the minimal polynomial.
So at this point — k = ? what?!?!?
First, before we go hunting it down — by convention we set the leading coefficient to 1, so
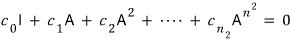
let’s set it like this.
It’s fine to just normalize this one thing!!!!! The other coefficients can absorb the scaling, right?
(For the record, a polynomial whose leading coefficient is 1 is called a monic polynomial.)
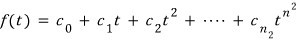
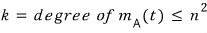
OK so first off —
even if we don’t know what the highest degree k of
$m_{A}\left( t \right)$
actually is,
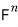
it’s smaller than this.
Let’s think about a certain set of matrices.
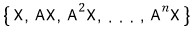
The matrices inside this set can do addition freely, and you can also do scalar multiplication freely.
So
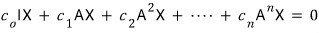
we can see this is also a vector space.
And the dimension of that vector space is
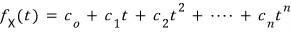
!!!!!!!!!!!
Not hard to see —
if you think about the basis of
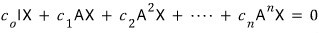
it pops right out:
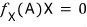
these 4 things, right????? Dimension is 4.
So the dimension is 2 times 2 = 4.
(But wait, didn’t we already settle that k is at most n???!!!!!!?!??!)
↓
Nope — that was when we knew Cayley-Hamilton.
Right now we’re rebuilding the whole thing step by step from scratch.
So what I’m trying to say is —
(The logic from here on down is going to keep showing up, so really nail it.)
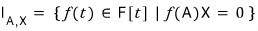
we got as far as: this kind of set has dimension n-squared.
Now from inside it I’m going to grab these elements:
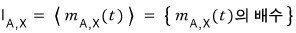
Say we pulled out this ‘subset.’ How many elements does it have right now????
“n-squared + 1”!!!!
The dimension of
is n-squared, but our subset has one more than that, so the subset is linearly dependent!!!!!!!
Let me write out a linear combination of those subset elements equal to 0:
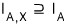
Since they’re linearly dependent, the tuple of coefficients does not all have to be 0.
Right?????!!!!!
So from that coefficient tuple let’s build a polynomial:
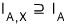
A polynomial whose highest degree is n-squared.
This polynomial gives 0 when you plug A in,
so it’s one of the elements of
$I_{A}$,
and that element has to be a multiple of
$m_{A}\left( t \right)$.
So
$m_{A}\left( t \right)$
is, for now, smaller than n-squared!!!!
So to recap —
the elements of the set
$I_{A}$
show up in the form of multiples of some polynomial,
and the one of minimum degree among the polynomials that vanish when A is plugged in is what we define as
$m_{A}\left( t \right)$,
and after going through the discussion above, we now know that
the degree of
$m_{A}\left( t \right)$
is — for now — smaller than n-times-n, the size of matrix A.
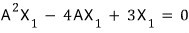
And next!!!!!!!
Different story now.
Let X be an arbitrary vector in n-dimensional space.
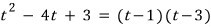
Then
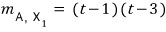
is n-dimensional, so
any subset with n+1 elements is 100% linearly dependent!!!!!!!
Let me put it this way:
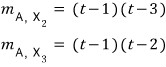
Like this — we keep multiplying by A one more time to build up a set,
and once we have n+1 of them, no question, it’s linearly dependent!!!!!
(Announcing: same logic as above, here it comes lol lol lol lol)
(This is actually using a concept called the L-cyclic basis — I’ll clean up the terminology below.)
By the count alone it can’t satisfy the independence condition, so it’s 100% linearly dependent, no way around it!!!!!!
OK linear combination time!
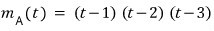
The c coefficients that make this equal zero — they don’t all have to be 0!!!! Because it’s linearly dependent.
We’re going to give birth to another polynomial:
if we define it like this —
(The subscript X under f means ‘for some specific X.’ If we used vector Y, or vector Z, and ran the same logic, the coefficients would all be different, right?!?!?!?!?!?!?
So we slap an X subscript on f to keep them straight.)
That is — in this polynomial, if we plug A into the t spot and then multiply by X,
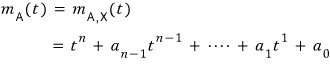
we can recreate this form, right?!?!?!
So,
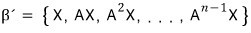
this means we can satisfy this equation.
What I’m trying to say is —
for any arbitrary vector X, there exists an f(t) of degree at most n, and there’s a polynomial such that f(A)X = 0.
Now to make use of the second part —
I’ll create one more set.
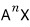
The set of polynomials such that, when you plug A into f(t) and then multiply by vector X, you get 0!!!
This set is also closed under addition, subtraction, and multiplication, so we can call it the set of multiples of some polynomial.
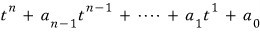
Of course,
the degree of
$m_{A,X}\left( t \right)$
is going to be at most n!!!!!!
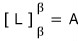
Tracking down k, we’ve ended up at
$k_{X}$.
But just so we don’t lose the thread, let me put it this way:
“We are currently in the middle of hunting down the identity of k.”
OK so —
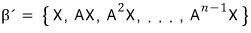
the set where you have to plug A in and multiply by X to get 0 obviously contains the set where just plugging A in is enough, right?!?!?!?!?!?!?
So
inside
$I_{A,X}$
there are going to be polynomials that don’t give 0 from just plugging A in!!!!
That’s what’s being said here, well~~~
Anyway, makes sense.
Whoa!!!!!!!!!!!!!!!! But!!!
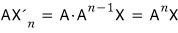
what this means is —
every element of
$I_{A,X}$
has to be a multiple of
$m_{A,X}\left( t \right)$
in the first place,
so
$m_{A}\left( t \right)$
becomes a multiple of
$m_{A,X}\left( t \right)$
is what we’re saying!?!??!!!!
<Bonus side comment you don’t strictly need>
$m_{A,X}\left( t \right)$
is a divisor of
$m_{A}\left( t \right)$.
Polynomials inside
$I_{A,X}$
are divisible by
$m_{A,X}\left( t \right)$,
right?
Then the
$m_{A}\left( t \right)$
sitting inside there is also divisible by
$m_{A,X}\left( t \right)$
!!!!!! Got it?!?!?!
So
$m_{A}\left( t \right)$
has higher degree than
$m_{A,X}\left( t \right)$.
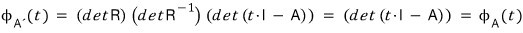
And then —
inside the set
$I_{A,X}$
we can track down
$k_{X}$.
Same logic as what we did above.
Like this!!!~~
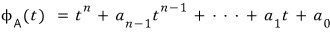
To give an actual concrete example:
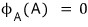
we have this kind of matrix,
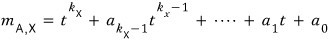
and like this,
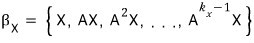
let’s say these exist as a basis of 3-dimensional space.
Now let’s pull the same stunt on X1 that we pulled above.
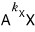
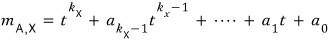
Taking the linear combination coefficients like this, we get 0.
O~~~~kay~~~
I’ll swap the matrix out for t.
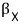
And we can say this about this polynomial:
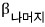
Because plugging in A and then taking X1 gives 0!!!!!!!!!!!!!!!!!
If we pull the same trick with X2, X3,
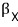
it comes out like this.
OK so
$m_{A}\left( t \right)$
has to be a multiple of
$m_{A,X}\left( t \right)$
for any X,
so it has to be divisible by all of those, which means
the candidate
$m_{A}\left( t \right)$
here is
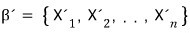
this!!!!!!!!!!!!!
Kind of feels like a least common multiple, doesn’t it.
Anyway — even without using Cayley-Hamilton,
we can see that the degree of
$m_{A}\left( t \right)$
is at least
$k_{X}$
!!!!!
Let’s push one more step from here!
When does
$m_{A,X}\left( t \right)$
actually equal
$m_{A}\left( t \right)$
directly?!?!?!?!?!
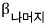
For something like this to happen, matrix A has to be kinda special,
and a special X vector matched to it has to exist,
and let’s just go ahead and assume all of that~~~ holds.
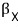
We assumed these n vectors are linearly independent.
Up to here they’re independent, but
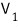
the moment we throw in this element!!!! it becomes linearly dependent, so the linear combination coefficients don’t all need to be 0, so by the same logic as before,
we can birth this polynomial:

So let’s call β’ the basis set such that, when you add
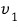
to it, it becomes linearly dependent.
(Meaning: adding one element to β’ makes it linearly dependent. β’ itself is linearly independent!!!!!!!)
The original matrix A was the representation of the linear map L in the β basis,
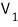
If we now represent the same linear map L in the new basis β’,
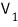
let’s call that matrix A’.
And let’s denote the elements of that β’ not as
but as

(Heads up — the subscript is one bigger than the exponent above.)
What that means is —
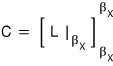
this is what it becomes, right?!?!??!?!
OK up to here — and now,
into the polynomial
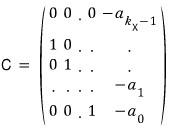
when we plug A in,
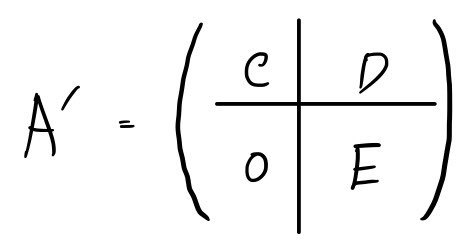
it’s 0!!!!
Shall we multiply both sides by X?
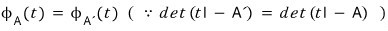
The red part isn’t a basis, is it?!?!?!!!!!
So,

Let me restate what we’ve been going at this whole time by setting up the actual situation.
If we represent it in this well-chosen basis β’,
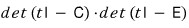
the shape

ends up like this. (Reason coming up shortly.)
The matrix A’ built this way is called a companion matrix,
and if you look carefully — the rightmost column comes out as negative a(0) through a(n-1) from top down,
and all the diagonal elements of the remaining columns are alllllll 0, with 1s right below them on the subdiagonal.
Ugh…T_T T_T what is this T_T T_T T_T T_T
Why does this kind of matrix represent what we’ve been working with?!?!?!?!?!!!!
Let me write out why.
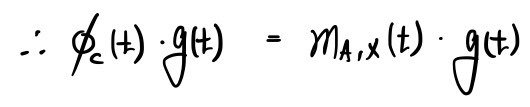
are, in the basis β',
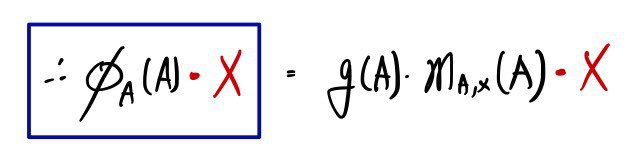
these unit vectors, right?
If we hit each of these unit vectors with A',
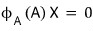
it comes out exactly as written before!!!!!!!!!!!!!!!!! Yesss!
Now let’s look at the characteristic polynomial of A vs. the characteristic polynomial of A'.
Since A and A’ only differ by basis representation, they’re similar, so
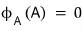
this holds, which means
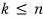
playing with this formula a little using the relations above,
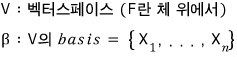
since we can swap the order,
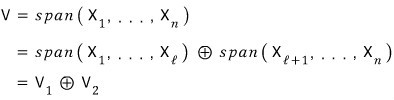
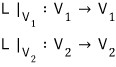
using this, let’s gradually crank up the size starting from n=1 (we need to find the characteristic polynomial of the companion matrix!!!!!)
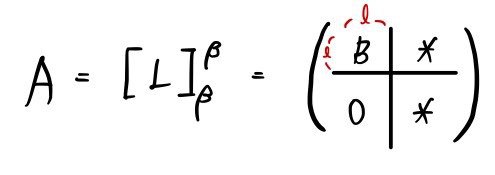
Ahhh!!!!!!!!!!!!!!!!!!
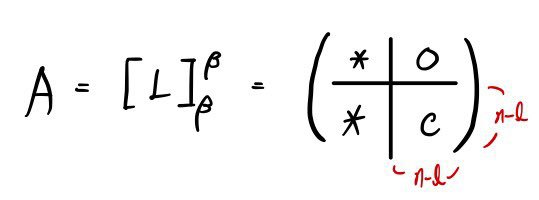
So,
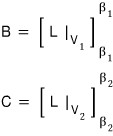
Only now can we land the conclusion: the companion matrix is one whose characteristic polynomial and minimal polynomial are the same!!!!
Whoa!!!!!!!!! (Bonus: we ended up proving C-H one more time as a freebie.)
Now let’s switch up our thinking.
X is now just any arbitrary vector!!!! (going more general here)
Let the minimal polynomial for that X be
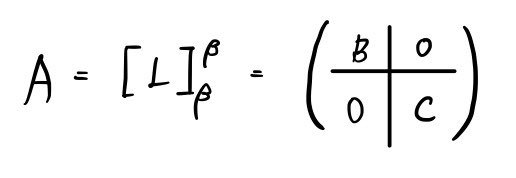
like this.
In that case,

let’s take this as a basis —
obviously these k(X) guys are linearly independent.
The instant we add
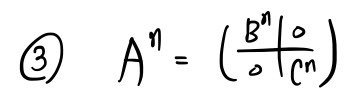
this element, it becomes linearly dependent,
and we could use the polynomial in the form
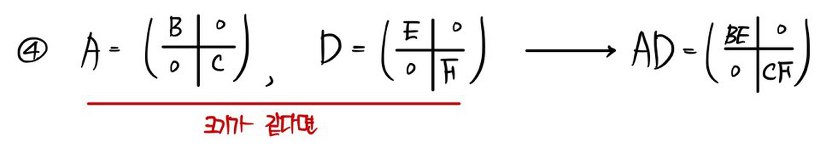
above.
Now —
inside
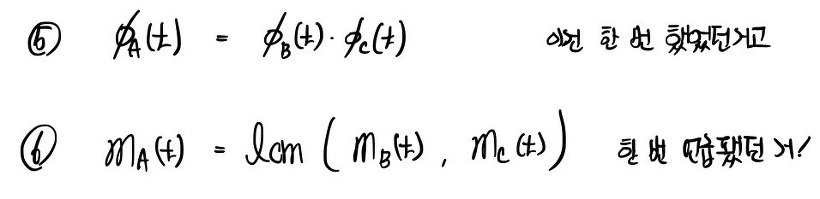
it’s totally possible that
$k_{X}$
doesn’t reach n.
So,
with the further-built-up set
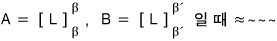
and
their union
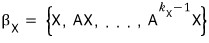
let’s form this.

Same as above, let’s give it an alias for now.
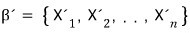
Now, the linear map L represented in basis β was
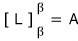
this — and
if we represent it in basis β’, what does A’ look like? Let me write it out write it out write it out write it out.
Same as before,

by the same principle,
from
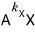
onwards it’s linearly dependent, so
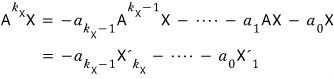
Look back carefully!!!!
What we need to look back at is —
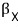
the work was done only among these guys, between themselves.
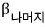
hasn’t been looked at at all yet.
That is —
if we call the subspace spanned by
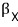
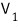
this,

then using L,
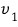
can’t be sent outside of
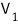
and in this case
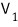
is called an “L-invariant subspace”!!!! (I’ll add a bit more on this in a sec.)
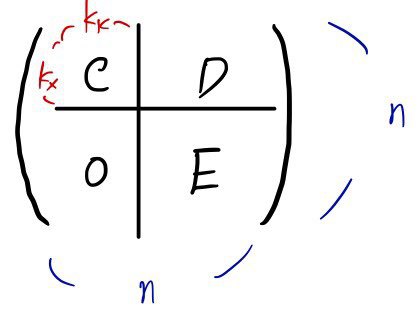
So the shape of A’ up to here
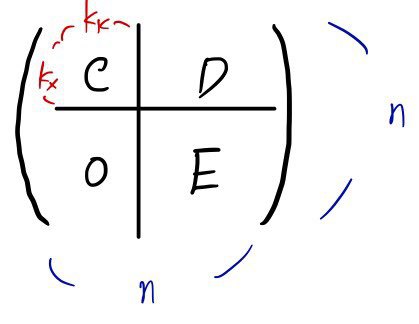
forms a square block like this!!!!!!
Looking at the matrix shape,

doesn’t this become understandable too?!?!?!
The C and the 0 part are what matter here.
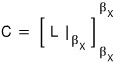
The matrix C ends up in the companion matrix shape we argued above (the expressions are the same too),
and it’ll look like this:
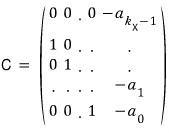
This matrix
can also be thought of as the companion matrix of
$m_{A,X}\left( t \right)$
!!!!!
Let’s find the characteristic polynomial of
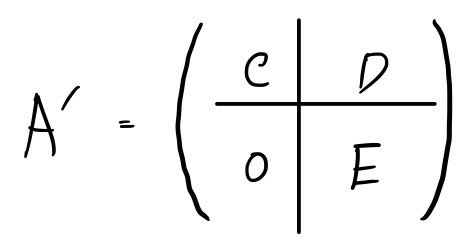 .
.
Since A and A’ are similar, their two characteristic polynomials are the same.
(We did this above!)
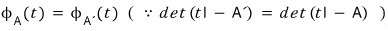
But!!!!

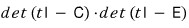
each is a characteristic polynomial, so

Since C is a companion matrix, the characteristic polynomial of the companion matrix equals the polynomial that gave birth to it…!!!!
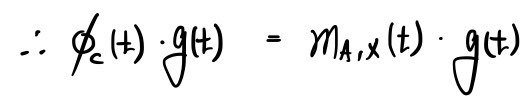
we can write this, right?!?!?!!!!
And on the right side,
the polynomial
$m_{A,X}\left( t \right)$
is by construction a polynomial that, when you plug A in and multiply by X, gives 0 — so
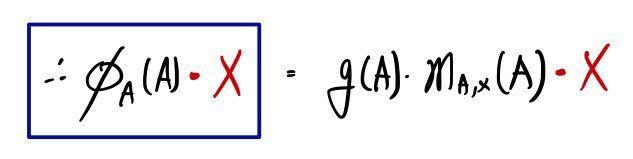
the right side equals zero!!!!!!!!!!!
For any arbitrary vector X,
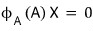
the fact that this is 0 is — apparently — worth paying attention to.
The fact that it’s 0 no matter what vector X you stick in means
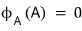
because of this,
and so we just ended up proving C-H yet another way, for the third time……….
About the degree of
$m_{A}\left( t \right)$ —
elements inside
$I_{A}$
are elements (multiples) of
$m_{A}\left( t \right)$,
so
if the degree of
$m_{A}\left( t \right)$
is k, and the characteristic polynomial has degree n (the dimension of the whole space), then
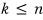
that’s what we should say.
A quick note on the L-invariant subspace (L-invariant subspace).
We’re going to apply L-invariance to explain block-ifying a matrix (i.e. decomposing a vector space, or decomposing a matrix), which is gonna be our concern soon.
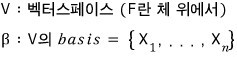
The vector space V is built by spanning the elements of β,
and let’s say it gets split like this:
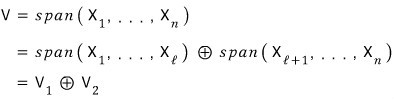
Meaning: the basis of V1 is the first chunk,
and the basis of V2 is the second chunk.
Now think of some linear map L, with L going V → V.
If β1 and β2 are picked really well, can we make both V1 and V2 be L-invariant subspaces?!?!?!?!?
What that means: even if you push an element inside V1 through L, it stays in V1, and the same goes for V2.
In that case, since L can be thought of as L with a restricted domain,
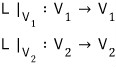
we can define it like this,
and if we call this linear map L the matrix A,
let’s look only at V1 —
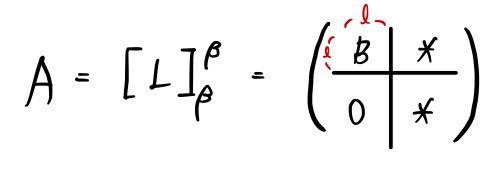
it’ll be this kind of matrix.
Now thinking only about V2, the linear map L as a matrix is:
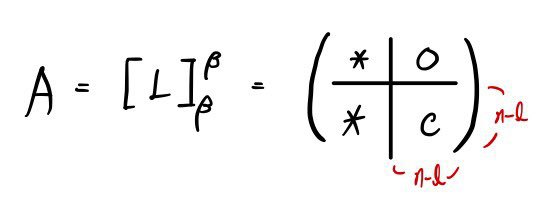
inside this, the matrices B and C are respectively
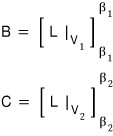
like this,
and so for A to satisfy both,
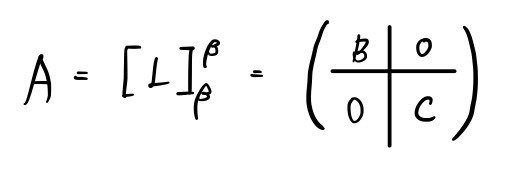
a split matrix like this shows up~~~~~~~~~~~~
Let’s organize what we know — old and new — about the “blockified matrix” we’ve found so far:


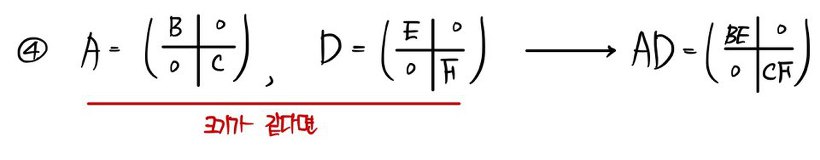
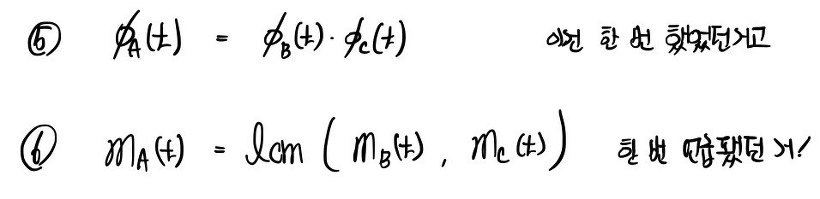
Stuff that into your head, and —
final summary!!!!!!
<Polynomials associated with an n × n matrix A>
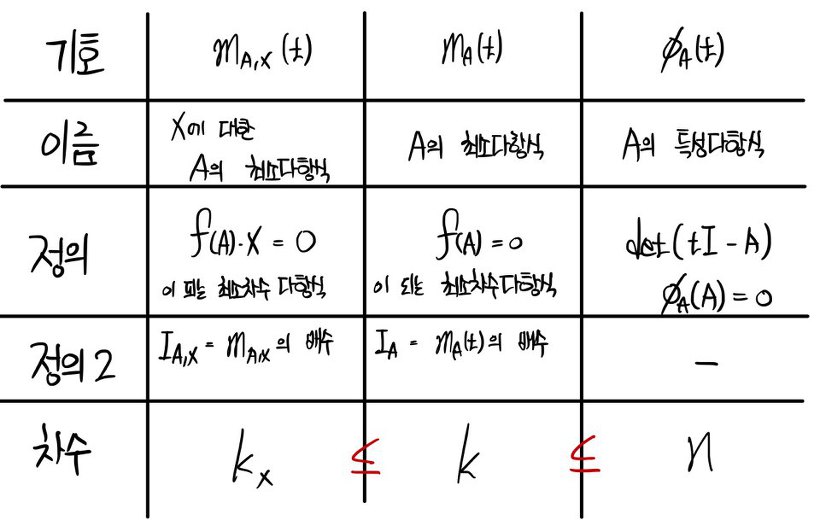
It’s gotten too long….I’m going to cut it here and pick it up next time. T_T T_T T_T T_T T_T T_T
Sorry…my writing’s a mess………T_T T_T
I’ll wrap up just one more piece of terminology and see you in the next post.
※ Terminology Notice ※
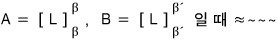
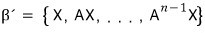
A vector X that turns this into a basis is called an L-cyclic vector, and the basis built from it is called an L-cyclic basis.
And the vector space built that way is called an L-cyclic space.
※ Terminology Notice ※
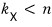
if this holds,
the (span) space made from
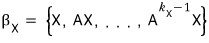
is called an L-cyclic subspace.
P.S.
Did you know?
All blog posts are being converted to PDF —
and PDF materials are for sale :-)
https://blog.naver.com/gdpresent/222243102313

Blog post PDF (ver.2.0) — for sale (the Physics and Finance I’ve been studying)
Purchase info below~~ Hello! If there’s anything unsatisfying in the blog posts, too many exces…
blog.naver.com
Originally written in Korean on my Naver blog (2016-02). Translated to English for gdpark.blog.
Comments
Discussion happens via GitHub Discussions. You'll need a GitHub account to comment.