Introduction
A casual dive into why sample variance divides by n-1 and how we use samples to estimate population parameters without measuring absolutely everyone.
OK so from here on out — like the category name says — I’m just gonna cherry-pick the basic stats stuff I actually feel like writing about.
I’ve done more than this, but I don’t really feel like I’m bringing any deep insight to the table here, so… I’ll leave that part to the folks who actually majored in statistics. I’m just gonna be a casual player.
And even when I say “basic statistics” — look, no matter how little stats you know, you already know what a population mean is, what a variance is, all that. And the stuff like $E(aX+b) = aE(X)+b$, $V(aX+b) = a^2V(X)$? Yeah, I’m not doing those either. That’s high school math…
Ahhh I dunno I dunno, let’s just dive in.
From the population to the sample…… wait, why on earth do you divide by $n-1$??????
Everything we’ve covered up to this point — like I was hinting at earlier — was about the population.
But hold on. Is it actually feasible to go analyze a whole population? Like… really??
Think about it for a sec. If you wanted to know the average height of people living in Seoul, you’d have to go measure every single Seoul resident. That kinda smells like overkill, right???
So in practice, what we do is pull a random sample out of the population and use that to estimate things about the population…
Example time —
Say a random variable $X$ follows some PDF (probability density function), and you wanna figure out the average number of cars a dealer sells during the first 10 days of every month.
But you obviously don’t have 10 years to sit around investigating, so you just surveyed last month’s sales for the first 10 days, and let’s say you got these 10 numbers:
9, 11, 11, 14, 13, 9, 8, 9, 14, 12.
Yep — that’s called a sample. And then —
The sample mean is the estimator of the population mean
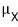
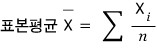
right?????
And the estimate from our sample mean is $(9+11+11+\cdots+12)/10 = 11$.
So 11 is our estimate.
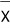
The estimate isn't always gonna match $E(X)$ (or
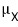
), but
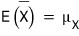
— yeah, this part is high school stuff.
But the *sample variance* — that one's different.
Because the population variance is
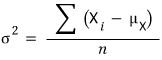
whereas the estimator of the population variance — we call it the sample variance, write it as $S^2$ — and $S$-squared is
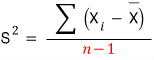
like this. *The denominator is different.*
(Why it's different — we'll see this when we hit the chi-square distribution section, where it'll become clear why it has to be $n-1$ to keep the estimator unbiased.)
OK let me just crunch the estimate for our example real quick!!!
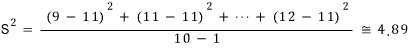
And the estimate of the population standard deviation is just the square root of that — so about 2.21 (yeah, I used a calculator~).
Alright. Now we move on to the topic of *distributions*.
The basic distributions you need to know in stats are: the normal, Poisson, exponential, Gamma, $t$, $\chi^2$ (chi-square), $F$ — and I'll be covering alllll of them!!!!! …is a lie, I really don't wanna do normal distribution T_T T_T T_T T_T T_T T_T T_T ~~~
My main major is physics, so I spent my whole life thinking the only distributions that existed in this universe were Gaussian, Poisson, Fermi-Dirac, and Bose-Einstein. So when I ran into all this stats stuff — honestly, full-on culture shock.
So shall we touch on the normal distribution first????????????????
…I was *going* to — but —
actually, I think it'd be way better to know the moment generating function before that.
So I'll do MGF first!!
## Moment Generating Function
Ahhh wait — you know what, should I just push this to the next post???
Yeah let's do that >_< !!!
---
*Originally written in Korean on my [Naver blog](https://blog.naver.com/gdpresent/221138159144) (2017-11). Translated to English for gdpark.blog.*
Comments
Discussion happens via GitHub Discussions. You'll need a GitHub account to comment.